
C语言浅学-字符串的格式化输入输出
在总结完数据类型之后,我们就开始对printf()和scanf()中都有的格式化字符串进行学习和探讨。
字符串简介
字符串是一个或多个字符的序列,一般使用双引号将内容括起来,正如单引号对于字符一样。
1 | "Zing went the strings of my heart!" |
char类型数组和null字符
在C语言中没有专门用于储存字符串的变量类型,一般被储存在char类型的数组中,每个单元储存一个字符。

上述数组的末尾的字符\0,这是空字符(null字符),C语言用它标记字符串的结束,空字符不是数字0,它是非打印字符,其ASCII码值是0。C的字符串一定是以空字符结束,也就是说数组的容量至少要比存储字符串的字符数多一。
数组:一行连续的多个储存单元,同类型数据元素的有序序列。
1 | char name[40]; |
char是声明变量的数据类型,name是数组的名字,方括号表明这是一个数组,40则是说明该数组的数量。
字符串的使用
转换说明:%s
我们不需要把空字符放到字符串结尾,scanf()在读取输入时就已经完成这项工作了,编译器也会在末尾加上空字符。
Tip:scanf()只会读取连续的字符,从第一个非空白字符起到空白字符结束。下面将会进行详尽阐述
字符串和字符的区别:”x” 和 ‘x’ 就是不一样的,前者是char数组,后者是char类型;前者在末尾还有空字符,而后者则没有。
Strlen()函数
在数据类型的博客中我们介绍了一个sizeof运算符,它以字节为单位给出对象的大小。strlen()函数给出字符串的字符长度,因为一个字节储存一个字符,但其实这两种方法应用字符串的结果并不相同。
1 |
|
上面的程序中 sizeof 运算符报告name数组有40个存储单元,但是只有前11个用来存储,所以strlen()得出的结果是11。一般来说 sizeof 运算符给出的数更大,因为它要把字符串末尾的空字符也计算在内。
Tip:sizeof 运算符使用圆括号的场景,取决于运算对象是类型还是特定量。运算对象是类型,则必不可少;若是特定量则可以省略,但还是建议在所有情况加上()。
常量和预处理器
在程序中,我们使用一个常量一般都是直接键入,虽然无需声明,但是不够好,我们可以使用符号常量。一般使用符号常量有两种方法:
1.声明一个变量,给变量赋予所需的值:
1 | float tax; |
虽然这样做提供了一个符号名,但是 tax 本质是一个变量,复杂的程序在运行中可能会无意改变它的值。
2.C预处理器:
1 |
在前面博客介绍过预处理器是如何使用 #include 包含其他文件信息,但同时预处理器也可以用来定义常量。
通用格式:#define NAME value
#define 指令还可以定义字符和字符串常量,前者单引号,后者双引号:
1 | #define BEEP '\a' |
const限定符
在C90标准中新增了const关键字,用于限定一个变量为只读。
1 | const int num = 32; |
num 这个值成为一个只读值,不能更改。
Tip:const 定义的是一个只读变量,而不是常量。
后面的博客再来详细介绍。
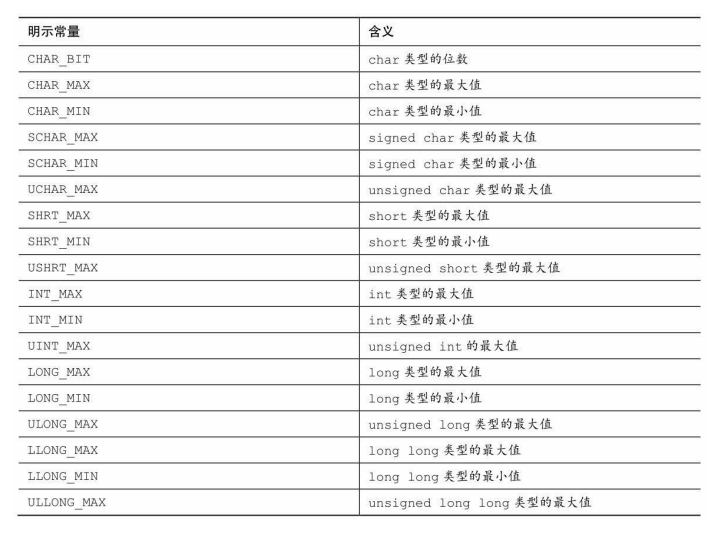
明示常量
C头文件limits.h 和 floar.h 分别提供了整数类型和浮点类型大小限制相关的详细信息。
在limits.h头文件中包含以下代码:
1 |
下表是limits.h中一些明示常量:
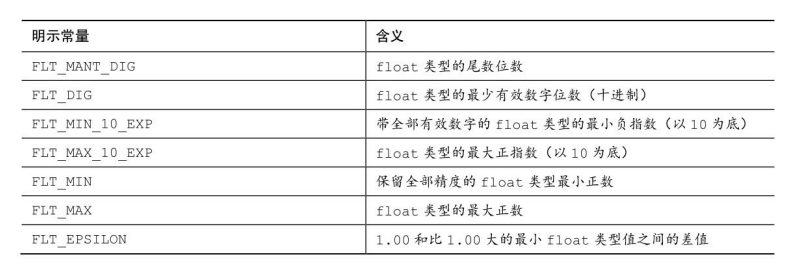
类似的,下表是一些float.h中的一些明示常量:
printf()和scanf()
这个两个函数对于C语言学习者来说并不陌生,一个输入函数,一个输出函数;工作原理几乎相同,都是使用格式化字符串和参数列表。
printf()函数
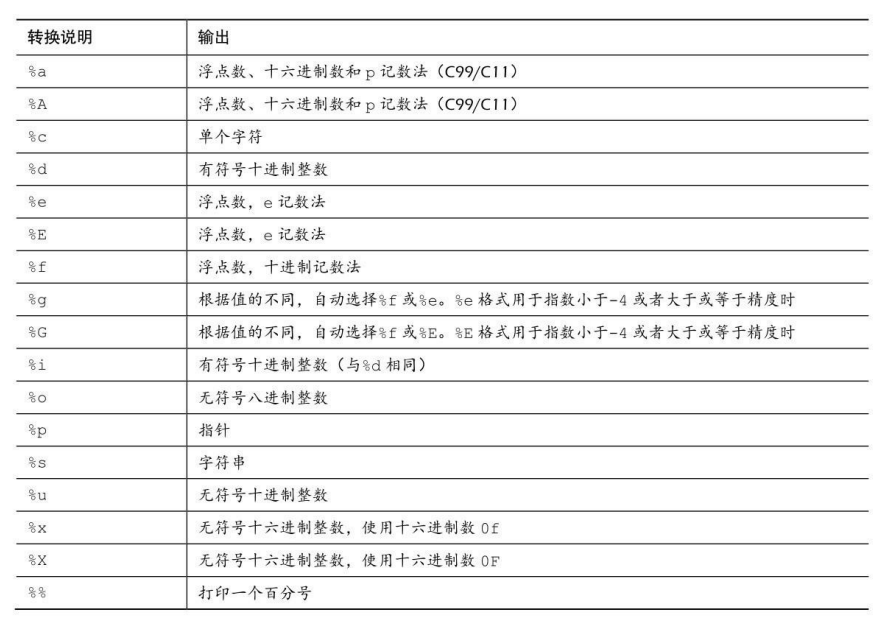
在请求printf()函数打印数据的指令要与待打印数据的类型相匹配。打印整数使用%d,打印字符要用%c,这些符号被称为转换说明:
printf()函数的使用
打印输出函数的使用就需要在这里赘述了,简单说一下格式即可:
格式:printf(格式化字符串,待打印项1,待打印项2,…);
其中待打印项1等都是需要打印的,它们可以是变量,常量,甚至是打印之前要计算的表达式,前提是格式化字符串应当包含每个待打印项对应的转换说明;数量和类型都要对应。
若是只打印短语或句子,就不需要使用任何转换说明;如果只打印数据,也不用加入说明文字。
1 | printf("Hello world!\n"); |
Tip:由于%在printf()函数中拿来标识转换说明了,因此打印%符号就需要用别的方法,然而我们之前有使用过 \ (反斜杠)的转义字符来表示符号,但在这里并不适用,我们只需要使用%%即可。
printf()的转换说明修饰符
在%和转换字符之间插入修饰符可以修饰基本的转换说明,下面列出一些可作为修饰符的合法字符,若要同时插入多个字符,也得与下表顺序相同。(并非所有的组合都可行)


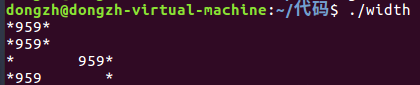
代码示例:
1 |
|
上述代码展示的是对于字段宽度以及修饰符的作用。
上面是对于整型来说的,下面我们看看对于浮点型来说,修饰符又有那些作用呢:
1 |
|
该程序输出结果如下所示:
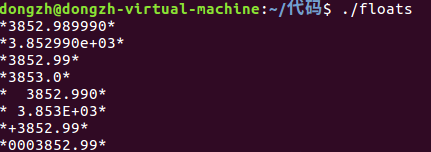
该程序中使用了const 关键字,限定变量为只读。
第一个转换说明%f ,在这种情况下,字段宽度和小数点后面的位数均为系统默认设置,小数点后打印6位数字。
第二个转换说明%e 无需过多的赘述,在数据类型的博客中有详细讲解。
第四个和第六个例子分别对输出结果进行四舍五入。
第七个转换说明中包含了+标记,这使得打印的值前面多了一个代数符号;最后一个转换说明的 0 标记使得打印的值前面用 0 填充来满足字段的要求。
剩下的一些其他格式的数据在这里就不逐个展示了。
Tip:在整型数据中使用精度(%5.3d)生成足够的前导0 用来满足最小位数的要求,若是精度和 0 同时出现,0 标记会被忽略。
对于字符串格式来说:
1 |
|
虽然第一个转换说明是%2s ,但是字段会被扩大为可容纳所有字符的格式,另 . 5是告诉打印函数只打印5个字符,- 号则是使得文本左对齐输出。
转换说明的意义
在介绍了这么多转换说明和修饰符之后,我们应该深入了解一下转换说明的存在意义,实际上转换说明就是把电脑中存储的二进制格式的值转换成我们所需的一系列字符。转换本质上是翻译说明,而非替换;无论输出格式如何多种多样,数据存储的方式都只有二进制一种。
转换说明会碰到的问题:
1.转换不匹配:
通常我们打印一个 int 类型的值,我们可以使用%d ,%x ,%o ,类似的,打印float 类型的值,我们可以使用%f ,%e ,%g 。
在这个转换说明中可以着重看一下原码,反码和补码的概念,但是我们同样需要注意%u 不会把数字和符号进行区分。
1 |
|
上述代码说的都是整型数据中的错误,若是错误出现在浮点型中时,出现的结果会更令人意想不到。
1 |
|
第一行中除了n1和n2两个值之外,n3和n4这两个值输出都并不正常,这里我们就需要说到在printf()函数中,float类型(4位字节)会变成double类型(8位字节)进行输出,使用%e 打印long类型(4位字节),除了查看本身的4位之外,还会额外查看相邻的4位字节,共同组成解释浮点数。即使n3 位数正确,最终得到的结果也是无意义的值。
在第三行中输出显示,printf()函数即使使用正确的转换说明也可能会生成虚假的结果,其中的问题就出在了C语言的信息传递过程中。参数传递过程会因为系统和编译器的实现方式而出现变化。
上面程序的第三句输出,n1是作为double类型存储到栈的内存区域占8位字节,n2 同样也是占8位,n3 和 n4 各自占据了4位字节,然后才是函数根据不同的转换说明进行数据的读取,%ld 说明应该读取4个字节,然而前4个字节是n1 的前半部分,这样的读取就出现错误。n2 则是读取了n1 的后半部分。虽然用对了转换说明,却读不出正确的值。
Tip:从这里可以看出计算机其实非常的死板,只能按部就班的完成指令
2.printf()的返回值:
在C语言起始那篇博客中,我们介绍过大部分C语言函数都会有一个返回值,这是函数计算并且返回给主调程序的值,总之程序中可以把返回值像其他值一样使用。printf()的返回值是函数打印之后的附带用途,一般很少用的到,一般是检查错误用到比较多。(写入文件的时候比较常用),若是一张CD拒绝写入时,程序采取相应的行动。要实现需要先了解 if 语句。
1 |
|
上述程序就展示了printf()在正常运行时的返回值。计算了所有的字符数包括空格和不可见的换行符。
3.打印较长的字符串
在打印字符串时,我们经常会碰到较长的语句,在屏幕上不方便阅读,若是有空格、制表符、换行符等用于分隔不同的部分,C编译器会忽略他们,所以一条语句可以写成很多行,在不同部分之间输入空白即可。
Tip:切记不能在双引号括起来的字符串中间断行,会产生报错。
给字符串断行的三种方法:
1.我们可以使用多个printf()语句,因为第一个字符串没有以\n字符结束,所以第二个字符串会紧跟第一个字符串的末尾。
2.用反斜杠(\)和Enter键组合的方式来断行,这使得光标移到下一行,而且字符串不会包含换行符。
3.ANSI C 引入的字符串连接,在两个用双引号括起来的字符串之间用空白隔开,C编译器会把多个字符串看作一个字符串。
1 |
|
输出结果:

scanf()的使用
结束了printf()函数的学习,接下来介绍一下scanf()函数,C语言库中包含很多的输出函数,scanf()是其中最通用的一个,因为它可以读取不同格式的数据,但是从键盘输入的都是文本字符:字母,数字和标点符号,要把字符依次转换成数值就是scanf()函数需要做的事情,与printf()所做的事情正好相反。
Tip:printf()整数、浮点数、字符串–> 文本
scanf() 文本 –> 整数、浮点数、字符串
这两个函数的核心本质都是格式化字符串。
scanf()函数中用的最多的是指向变量的指针,关于指针的内容后续再详细介绍,这里我们只需要知道两条规则:
1.如果用scanf()读取基本变量类型的值,在变量名前加上一个&。
2.如果用scanf()把字符串读入字符数组中,不要使用&。
示例程序:
1 |
|
上面包含了整型、浮点型和字符串三个数据类型。
Tip:在scanf()函数中唯一的例外是%c 转换说明,根据%c ,scanf()会读取每个字符,包括空白。
scanf()函数所用的转换说明与printf()函数几乎相同,主要的区别是对于float类型和double类型,printf()都使用%f ,%e ,%g。而scanf()函数仅仅把这几个用于float类型,对于double类型需要加上l 修饰符。
具体的转换说明如下图:

修饰符如下图:
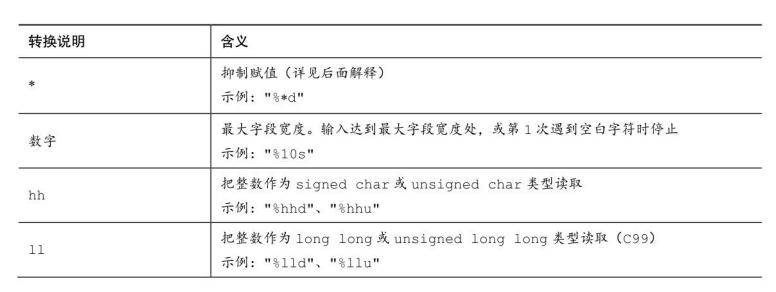

Tip:若要同时使用多个修饰符需要严格按照修饰符的顺序。
从scanf()看输入
scanf()函数读取输入若是%d ,一开始会跳过所有的空白字符,直至遇到第一个非空白字符才开始读取,若是遇到数字或符号,继续读取,若还是数字继续,反之暂停。然后会把非数字字符返回给输入,也意味着下次读取会是上次丢弃的字符,这点很重要。
若是%d 遇到第一个非空白字符是A而不是数字,那么scanf()函数就会一直卡在第一个转换说明这里。若是多个转换说明,C语言规定会在第一个出错处停止读取输入。
如果使用的是%s 转换说明,scanf()会读取除了空白以外的所有字符。即非空白字符起,空白字符止。
C语言还有其他的输入函数,如 getchar()和 fgets()等。这两个函数更适合特殊的处理情况,未来碰到在详细介绍。
格式化字符串中的普通字符
scanf()函数可以把普通字符放在格式化字符串里,除了空格字符外的普通字
符必须与输入字符串严格匹配。
1 | scanf("%d,%d", &n, &m); |
1 | 88,121 |
1 | scanf("%d ,%d", &n, &m); |
1 | 88,121 |
上述代码就是输入一个数字,逗号,一个数字,逗号必须紧跟第一个数字,后面的间隔和空白并没有具体的要求。格式化字符串的空白意味着跳过下一个输入项前面的所有的空白。(所有的空白包括没有空格的情况)。
Tip:那么对于%c 来说,在格式化字符串中添加一个空格字符会有所不同,如果把空格放到格式化字符串的%c之前,scanf()会跳过非空白字符。若没有空格,那么会读取空白字符。
scanf()的返回值
scanf()函数返回成功读取的项数。如果没有读取任何项,且需要读取一个数字而用户却输入一个非数值字符串,scanf()便返回0。当scanf()检测到“文件结尾”时,会返回EOF(EOF是stdio.h中定义的特殊值,通常用#define指令把EOF定义为-1)。
printf()和scanf()的*修饰符
在这两个函数的修饰符中都有*修饰符,但是作用却完全不同。
在printf()中,若是不想预先指定字段宽度,希望通过程序来指定,可以使用* 修饰符来代替字段宽度,但是需要一个参数告诉函数,字段宽度是多少,也就是说转换说明%*d,参数列表应包含 *和d对应的值。这同样适用于浮点数的指定精度和字段宽度。
1 |
|
其中程序中的width是字段宽度,number是待打印的数值。
scanf()中的用法就和printf()不同,把* 放在%和转换字符之间时,会使得scanf()跳过相应的输出项。
1 |
|
printf()用法提示
在输出时想把数据打印成列,指定固定的字段宽度是很有用的,若是不指定的话,会显得数据显示的很杂乱。
1 | printf("%d %d %d\n", val1, val2, val3); |
1 | printf("%9d %9d %9d\n", val1, val2, val3); |
1 | 12 234 1222 |
这样就会显得整齐不少,在两个转换说明之间插入一个空白字符,可以确保即使一个数字溢出了自己的字段,下一个数字也不会紧跟一起输出。
总结
到此我们结束了对于这两个函数的使用包括修饰符等,也对数据类型进行了巩固,下一篇将进入运算符和表达式包括语句的学习。
 wechat
wechat alipay
alipay
